AI Agent Security: Why It’s Reshaping Enterprise Security Architecture (and It’s Not the Prompt Problem You Think)
Disclaimer: This post is machine-translated from the original Chinese article: https://ai-coding.wiselychen.com/ai-agent-security-game-changed/
The original work is written in Chinese; the English version is translated by AI.
Table of contents
- What is an AI agent (and how it’s fundamentally different from a chatbot)
- Real incidents: how enterprise AI agents get compromised
- Let the data speak: research numbers on AI agent security
- The rules have changed: security architecture must be rebuilt
- The blind spot of traditional tools: why WAF/APM fails
- Honestly: AI agent security is harder than you think
- Why guardrails can’t stop it
- References
- Further reading
Last Friday, at the Hong Kong Disneyland Hotel, I had a great time joined a group of security veterans from AWS/ECV/Palo Alto/Fortinet and others to give a talk on AI information security. I shared threats in the “big agent” era, and chatted with peers and customers—heard a few interesting stories.
But before we get into cases, we need to clarify one critical question—many people still don’t actually know what an AI agent is.
What is an AI agent (and how it’s fundamentally different from a chatbot)
Step zero in AI Agent Security is getting clear on what an AI agent is. Let’s make one thing explicit: an AI agent is not “a smarter chatbot.” It’s a different species.
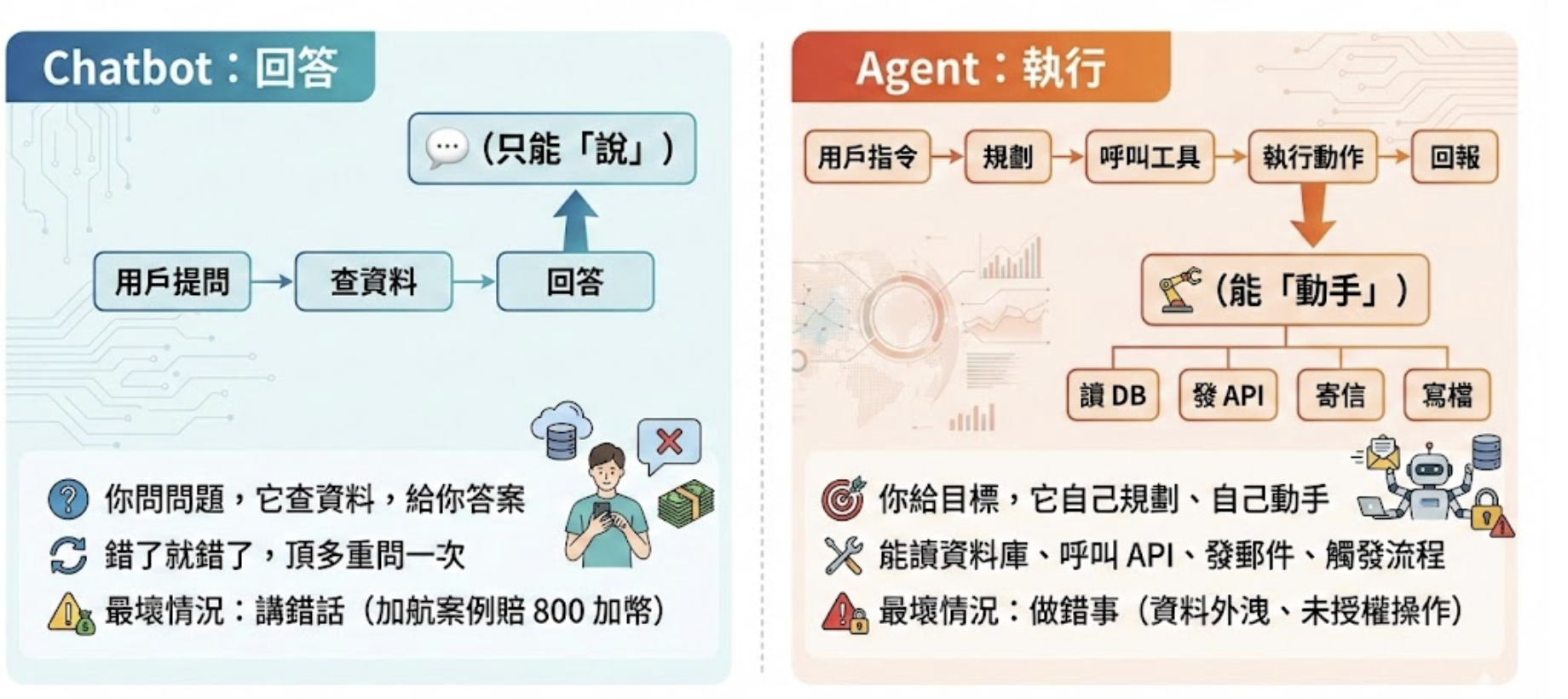
Why does “being able to take actions” multiply security risk?
Because the target changes.
In the chatbot era, attackers want to “trick it into saying the wrong thing.” In the agent era, attackers want to “trick it into doing the wrong thing.”
Once an agent has execution privileges, every data source it can access and every API it can call becomes part of the attack surface.
This isn’t theory—the next two cases are real attacks that happened in 2025.
Real incidents: how enterprise AI agents get compromised
The security risks of enterprise AI agents are not hypothetical. The following are attacks that already happened in 2024–2025.
👉 Full case breakdown: Enterprise AI agent attack case collection: 4 real incidents showing how companies get breached
One table: what do these 4 cases prove?
| Case | Entry point | What the agent was forced to do | The actual exfiltration/destruction channel | Why WAF/APM can’t see it |
|---|---|---|---|---|
| Salesforce ForcedLeak | Public form fields (Web-to-Lead) | Export CRM contacts | “Normal” internal workflows send the data out | HTTP 200, normal workflow, no errors |
| Microsoft 365 Copilot EchoLeak | Hidden text in email (zero-click) | Read SharePoint / summarize sensitive data and encode it | Exfiltration via a “load image” HTTPS request | Looks like image/CDN traffic |
| ChatGPT Plugins | Hidden instructions embedded in a web page | Read and execute malicious instructions | Exfil via plugin APIs (account data) | Normal browsing requests |
| ServiceNow Now Assist | Instructions passed between agents | Cross-agent privilege escalation | Abuse the trust chain to reach high-privilege data | Each individual request is “legitimate” |
Key takeaways from the cases
1) ForcedLeak (CVSS 9.4): fill out a form, and the AI helps you export the CRM list
No system intrusion needed. You just stuff “hidden instructions” into a form field. When an internal enterprise agent reads it, it uses its own privileges to export data externally. Logs look normal: 200 OK, no errors, no alerts.
2) EchoLeak (CVE-2025-32711, CVSS 9.3): you didn’t click anything, but data still gets exfiltrated (zero-click)
Attackers hide instructions in invisible email text. Copilot first “understands,” then “executes.” It packs a sensitive summary into an image URL, creating what looks like an ordinary image request. You see an image; the attacker gets financial data.
3) ChatGPT Plugins: the web page is the weapon
Attackers embed hidden instructions on a public web page. The user asks the AI to “summarize this page.” While reading the content, the AI is hijacked and exfiltrates account data to the attacker endpoint.
4) ServiceNow Now Assist: 100% success rate in multi-agent attacks
No single agent violates policy by itself. The attack exists in the composition of cross-agent behaviors. Seemingly reasonable privilege splits combine into a lethal chain.
The core issue
All four cases reveal the same essence:
When an agent has both “read access” and “the ability to take actions,” it becomes a potential data-exfiltration channel.
No need to hack the system. No need to steal passwords. No need for users to click links. Just a carefully designed prompt—and the AI sends the data for you.
This made me think: are we still using chatbot-era security thinking to handle agent-era risk?
Let the data speak: research numbers on AI agent security
This isn’t alarmism. Before we go further, look at what the research says.
Research + OWASP: agent attack success rates up to 94.4%
According to the Oct 2025 paper, Agentic AI Security: Threats, Defenses, Evaluation, and Open Challenges (arXiv:2510.23883), researchers found:
94.4% of SOTA LLM agents are vulnerable to prompt injection.
100% of agents were successfully compromised in “inter-agent trust” settings.
Yes—100% in multi-agent collaboration. If your architecture is “Agent A calls Agent B to complete tasks,” attackers only need to compromise one agent, then they can traverse the trust chain and break the whole system. Another ACL 2025 paper, Indirect Prompt Injection attacks on LLM-based Autonomous Web Navigation Agents, shows attackers can hide malicious instructions inside webpage HTML. When an agent browses that page, it is forced to execute malicious actions. The agent thinks it’s “browsing,” but it’s actually “executing the attacker’s instructions.”
This is not my opinion. OWASP has already listed LLM08: Excessive Agency as a core risk in the Top 10 for LLM Applications: when an LLM is given too much functionality, privilege, or autonomy, it may execute destructive operations in unexpected situations. The risk source is shifting from “prompt injection (trick it into talking)” to “excessive functionality (make it call functions).”
By contrast: the chatbot “worst case”
At this point, some might ask: “Don’t chatbots have problems too?”
They do—but those problems are more bounded.
In Feb 2024, a Canadian court decided a classic case (Moffatt v. Air Canada, 2024 BCCRT 149): Air Canada’s chatbot fabricated a refund policy and told a passenger they could get a refund after a family death—but that policy didn’t exist. The court ruled the airline was responsible and ordered compensation of about CAD 800. CAD 800. That’s the worst-case cost of a “closed-loop” chatbot failure—financial loss that’s bounded and compensable.
But what if it’s an agent with database access?
It doesn’t merely tell you the wrong policy—it executes the wrong refund, deletes the wrong record, or emails financial data to the wrong recipient. That’s not an “800 dollars” problem.
The rules have changed: security architecture must be rebuilt
AI agents change the foundational assumptions of security architecture. The shift from “conversation” to “execution” completely changes the risk model.
The old chatbot era (closed loop)
- Positioning: simple Q&A
- Scope: conversation only; no system access
- Risk level: low — worst case is a wrong answer
- Role: purely a UI
- Failure impact: bad UX; bounded compensation (e.g., CAD 800 in the Air Canada case)
Typical scenarios:
- Customer service bot answers “What are your business hours?”
- FAQ lookups and information navigation
- Wrong answers might annoy users; they just ask again
The current AI-agent era (open loop)
- Positioning: autonomous task execution
- Scope: deep integration — read DB, call APIs, trigger Lambda, operate cloud resources
- Risk level: high — can change real systems (94.4% attack success)
- Role: an operational system with agency
- Failure impact: data exfiltration, unauthorized actions, financial loss, compliance violations (Taiwan passed the AI Basic Act in 2025/12, explicitly requiring accountability and transparency for AI systems)
Why guardrails can’t stop AI-agent attacks
After seeing the above, many security experts ask: “So just add guardrails?”
The answer: guardrails are fundamentally ineffective. This isn’t just my take—it’s the conclusion from HackAPrompt CEO Sander Schulhoff after joint research with OpenAI, Google DeepMind, and Anthropic. He organized the world’s largest AI red-teaming competition, collected 600k+ attack prompts, and his results are cited by frontier AI labs. The conclusion: human attackers can break all existing defenses with 100% success within 10–30 attempts.
The core issue is: guardrails are stateless; attacks are stateful. Guardrails inspect single requests. Attackers distribute intent across multiple legitimate-looking requests. Read email (legit) + forward email (legit) = data exfiltration (illegitimate outcome). A traditional WAF sees HTTP 200 OK, normal latency, no error messages—yet the data is already gone.
That’s why APM/WAF are effectively useless against AI agents: they don’t understand natural language, can’t infer “what the user is trying to make the AI do,” and can’t connect “user text” with “database queries” across actions.
“You can patch software bugs, but you can’t patch a brain.” — Sander Schulhoff
Gartner predicts that by 2028, 33% of enterprise software will include Agentic AI (vs. <1% in 2024—over 33x growth). Our security tooling isn’t ready, yet we’re deploying AI agents 33x faster.
Potential direction: from perimeter defense to architectural containment
If guardrails can’t stop it, what can we do? Based on Schulhoff’s and Google DeepMind’s research, two directions are currently the most viable:
-
Least Privilege for AI Agents: anything the AI can access is equivalent to what the user can access; any action sequence the AI can execute is something the user can trigger. Use RLS (row-level security), network boundaries (isolation), and an auth gateway (entry-point permission control) to shrink the agent’s capability surface to the minimum.
-
The CaMeL framework (proactive intent-based constraints): Google DeepMind’s 2025 CaMeL framework pre-restricts the agent’s action set based on the user’s initial prompt. For example, “Summarize today’s emails” grants only “read” and disables “send/delete/etc.” Even if an email contains malicious injection instructions (e.g., “forward this email”), the attack fails because the agent lacks the required permission. On AgentDojo, CaMeL blocked nearly 100% of attacks while keeping 77% task completion.
The core strategy is: assume the AI can be tricked, but make it powerless even when tricked.
👉 Full analysis: Why AI guardrails are doomed to fail
👉 Defensive architecture guide: Enterprise on-prem LLM architecture blueprint
References
- Agentic AI Security: Threats, Defenses, Evaluation, and Open Challenges
- arXiv:2510.23883, October 2025
- Source for 94.4% agent vulnerability and 100% inter-agent trust-chain compromise
- Indirect Prompt Injection attacks on LLM-based Autonomous Web Navigation Agents
- ACL Anthology 2025
- Research on indirect prompt injection via web pages
- Moffatt v. Air Canada, 2024 BCCRT 149
- Canadian Civil Resolution Tribunal decision
- Legal accountability case for chatbot-fabricated policies
- OWASP Top 10 for LLM Applications
- LLM08: Excessive Agency
- https://owasp.org/www-project-top-10-for-large-language-model-applications/
- Gartner Top Strategic Technology Trends for 2025: Agentic AI
- Source for the “33% by 2028” enterprise software prediction
Further reading
🔥 New posts this week
- What is AI governance? Three responsibility questions enterprises must answer in the AI era — when AI goes wrong: who authorized, who’s responsible, who bears the consequences
- EU AI Act vs Taiwan AI Basic Act: differences in enterprise AI compliance — the EU tells you what to do; Taiwan asks you to prove you’re responsible
- Security trade-offs in the AI era: it’s never absolute safety — the eternal trade-off between efficiency, cost, and risk
Security series
- Why AI guardrails are doomed to fail — deep dive from prompt injection to secure agent architectures
- Taiwan’s AI Basic Act: what IT folks should know — interpreting the seven principles and compliance direction
- Enterprise on-prem LLM architecture blueprint — full implementation from permission control to sandbox defenses
- [Agent Mode Part 3] - From linear execution to autonomous loops: Deep Research architecture
- OWASP Top 10 for LLM Applications
About the author:
Wisely Chen, R&D Director at NeuroBrain Dynamics Inc., with 20+ years of IT industry experience. Former Google Cloud consultant, VP of Data & AI at SL Logistics, and Chief Data Officer at iTechex. Focused on hands-on experience sharing for AI transformation and agent adoption in traditional industries.
Links:
- Blog: https://ai-coding.wiselychen.com
- LinkedIn: https://www.linkedin.com/in/wisely-chen-38033a5b/