Implementing the CaMeL Agent Architecture in PostgreSQL: Designing Unbypassable AI Memory and Permission Isolation with RLS

Disclaimer: This post is machine-translated from the original Chinese article: https://ai-coding.wiselychen.com/camel-postgresql-implementation-memory-permission-db-layer/
The original work is written in Chinese; the English version is translated by AI.
What problem does this post solve?
- In practice, where should CaMeL’s “isolation wall” live?
- How do we prevent AI agent memory and permissions from being enforced only by application-layer if/else?
- How do we use PostgreSQL to build a security boundary an LLM cannot bypass?
1) The essence of CaMeL is not “two models”
In the previous post, I covered CaMeL’s two-layer agent architecture, based on Google DeepMind’s CaMeL paper. The core idea is to separate “reading data” from “taking actions”—the Quarantined LLM can only read untrusted data, and the Privileged LLM can only receive structured, cleaned information.
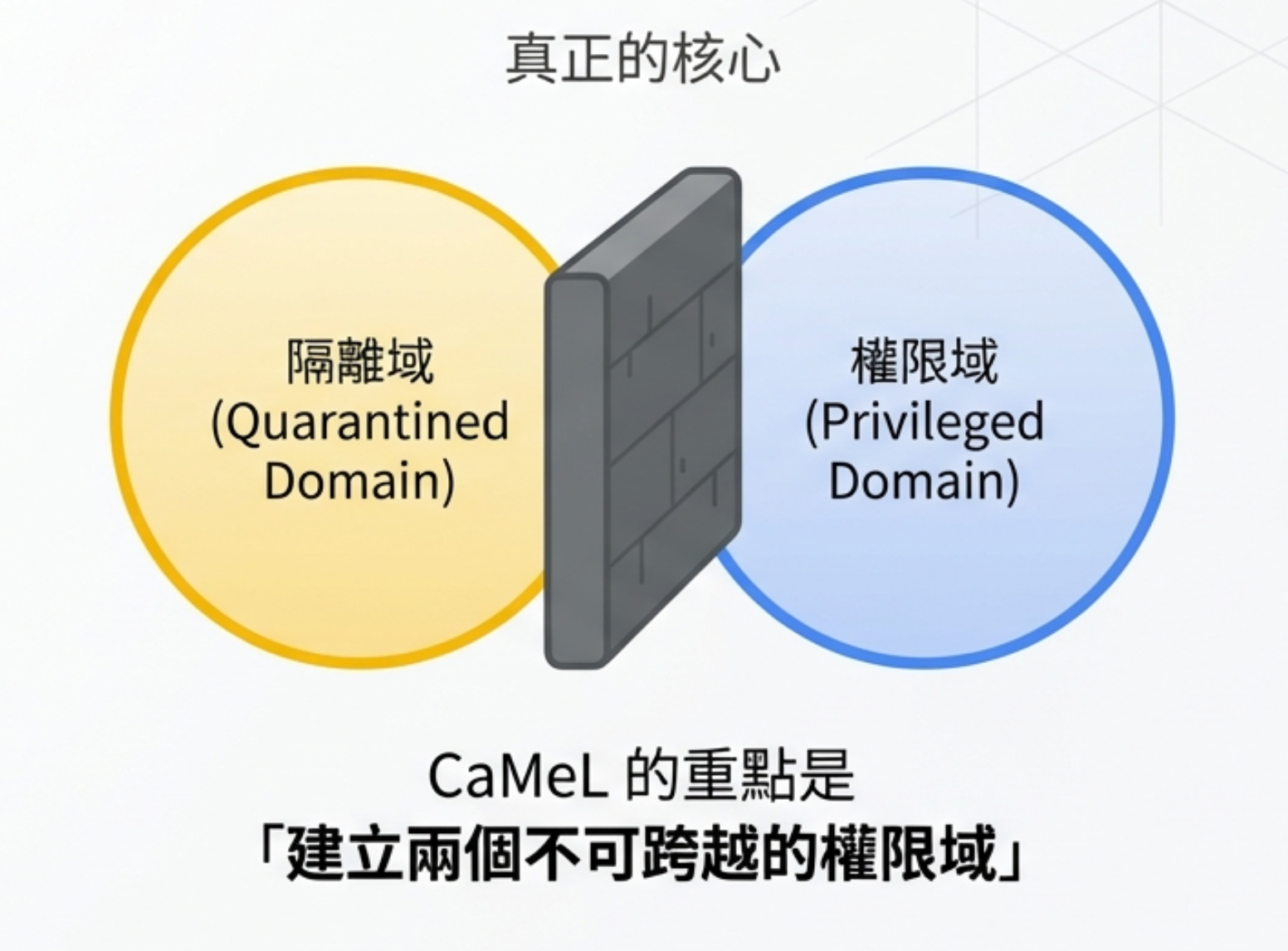
After reading the paper, I realized many people only get halfway.
CaMeL’s key isn’t “using two models.” It’s “establishing two permission domains that cannot be crossed.”
One side is the quarantined domain, which stores raw external inputs. The other side is the privileged domain, which may only access sanitized, trusted data. Between them is a wall: data must be reviewed before it can cross.
So the question is: where should we build that wall?
2) Application-layer if-else shatters on contact
Most teams’ first instinct is to enforce permissions in application code:
1
2
3
4
5
6
7
def access_data(agent):
if agent.role == 'privileged':
# Access sensitive data
return agent.get_sensitive_info()
else:
# Access public data
return agent.get_public_info()
The problem:
If your security boundary only exists as
if-elselogic in application code, then one wrong line of code can collapse the whole isolation scheme.
A new engineer doesn’t know the rule, a code review misses it, unit tests don’t cover it—any single failure and the privileged agent may directly see unsanitized external content.
This reminds me of a conclusion from my earlier post, PostgreSQL AI Memory Store:
Real security boundaries cannot live only in the application layer—they must sink down into the database layer.
3) The real security boundary must sink into the database
So I started implementing CaMeL’s concept in PostgreSQL.
The core approach:
Push both “memory” and “permissions” down into the database layer to create a boundary that application code cannot bypass.
We don’t ask the model to behave. We design the system so violations are impossible.
Even if the Python code is buggy, even if the privileged agent is tricked by prompt injection, the database engine itself blocks access—because the role simply does not have permission to touch that schema.
If you already have an enterprise on-prem LLM architecture with an auth gateway for identity and an LLM router for model dispatching, then database-layer permission isolation is the next “last line of defense” to add.
4) CaMeL’s three-layer memory architecture
The original CaMeL paper describes two layers (Quarantined vs Privileged). In real implementation, I found you need an explicit Sanitize layer in between.

The reason is simple:
You can’t let the quarantined agent directly produce “clean” outputs, so you need an explicit sanitize layer.
So we design three layers:
Layer 1: Quarantine
Table: quarantine.raw_memory
Stores all unprocessed external inputs—email, OCR results, API responses, web page content.
- Only the quarantined agent can write
- Mark
taint_level = 'external' - Short TTL (7–14 days)
Layer 2: Sanitized
Table: memory.sanitized_memory
Stores structured, trusted data produced by a sanitize pipeline.
- Only enters after a sanitize process
taint_levelmust be downgraded to'internal'- Privileged agents can only read this layer
- Keeps traceability links back to the raw source
Layer 3: Policy
Table: memory.policy_memory
Stores validated rules, conclusions, and playbooks.
- Long-lived decision basis
- Guardrails, playbooks, heuristics
- Highest-authority source for agent decision-making
5) DB roles: make agent permissions native to the database
This is the most important design choice: don’t do authorization in app code—let the database engine enforce it.
Why DB roles are safer than application roles
Application-role checks live in application code. One mistake, a missed review, or uncovered test path and the whole boundary collapses.
DB roles are enforced at the database engine layer—no matter how your Python or SQL is written, the engine blocks unauthorized access. This is the fundamental difference between “system-enforced” and “asking for self-discipline.”
Role definition
1
2
3
4
5
-- Create the role
CREATE ROLE agent_quarantined;
-- Set the role after connection
SET ROLE agent_quarantined;
Three core roles:
agent_quarantined: low-privilege agent; can only read/write its own quarantine areaagent_privileged: high-privilege agent; can only read sanitized and policy layersmemory_reviewer: reviewer role; promotes data from quarantine to sanitized
Switch role on connection
After connecting, switch based on agent identity:
1
2
3
4
5
6
7
-- Quarantined Agent after connection
SET ROLE agent_quarantined;
SET app.agent_id = 'agent_123';
-- Privileged Agent after connection
SET ROLE agent_privileged;
SET app.agent_id = 'agent_456';
The benefit: authorization happens in the DB engine, not the app layer.
6) RLS: an unbypassable system-level security gate
Row-Level Security (RLS) is the “security gate” of this architecture.
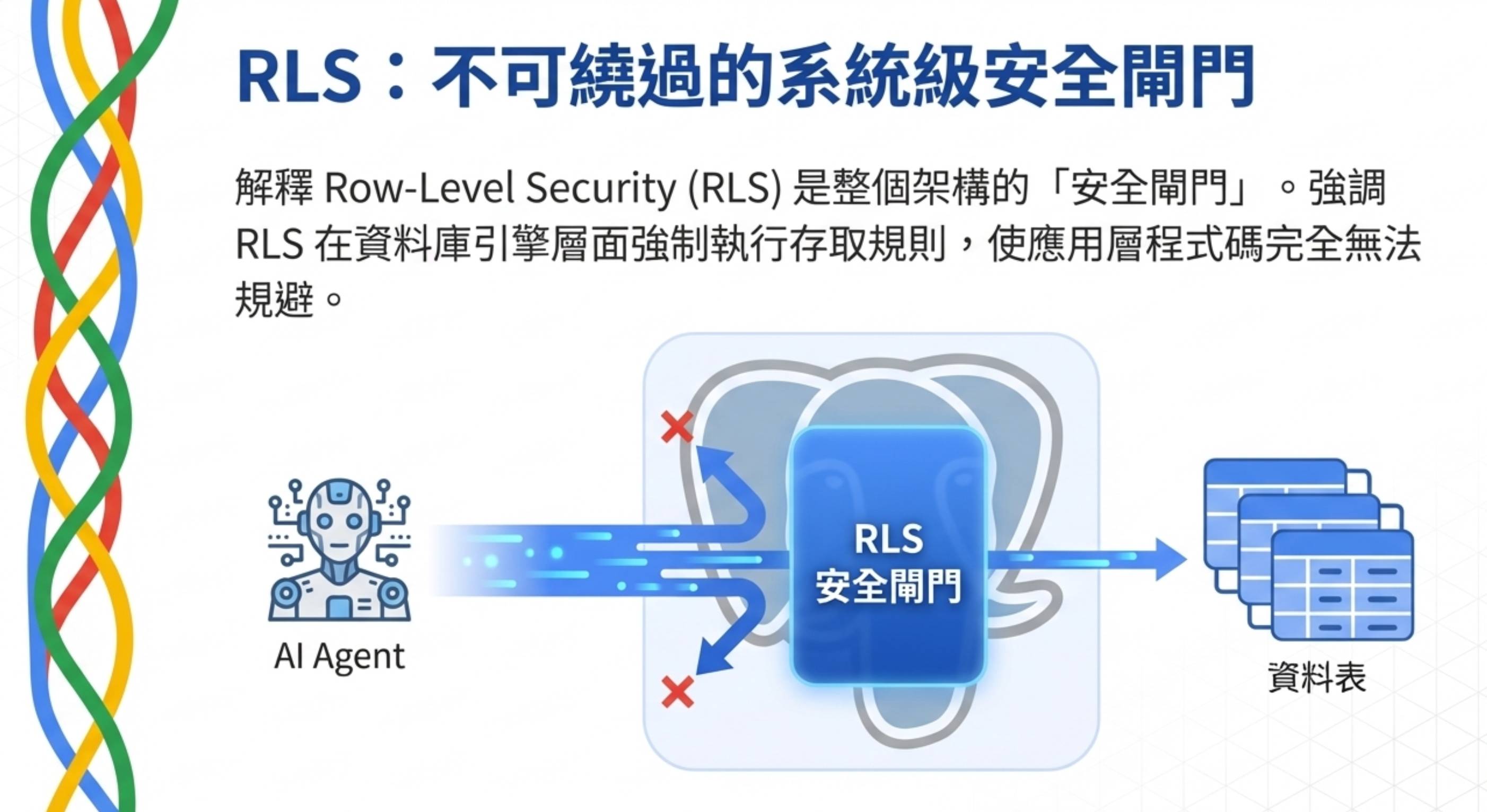
RLS enforces access rules in the database engine, so application code cannot circumvent them.
No matter how SQL is written, the engine automatically applies permission filters to every query.
7) The agent_quarantined view: read/write only its own quarantine
This agent can write to quarantine.raw_memory only for itself, and can only read what it wrote.
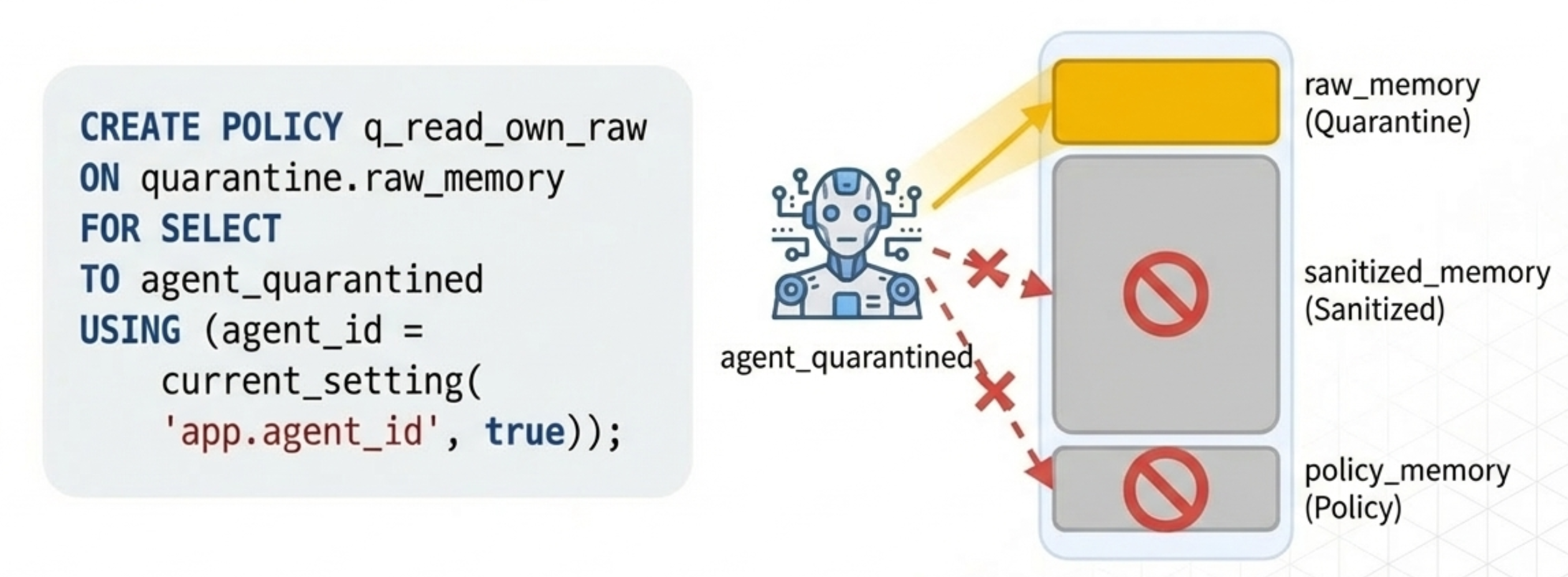
Key constraints:
- ✅ read/write:
quarantine.raw_memory(only its own) - ❌ cannot read:
memory.sanitized_memory - ❌ cannot read:
memory.policy_memory
8) The agent_privileged view: completely forbidden from the contamination source
The privileged agent is completely forbidden from accessing the quarantine schema—no permission even to look. It can only read clean data in sanitized_memory and policy_memory.
1
2
3
-- Forbid access to the entire schema
REVOKE ALL ON SCHEMA quarantine
FROM agent_privileged;
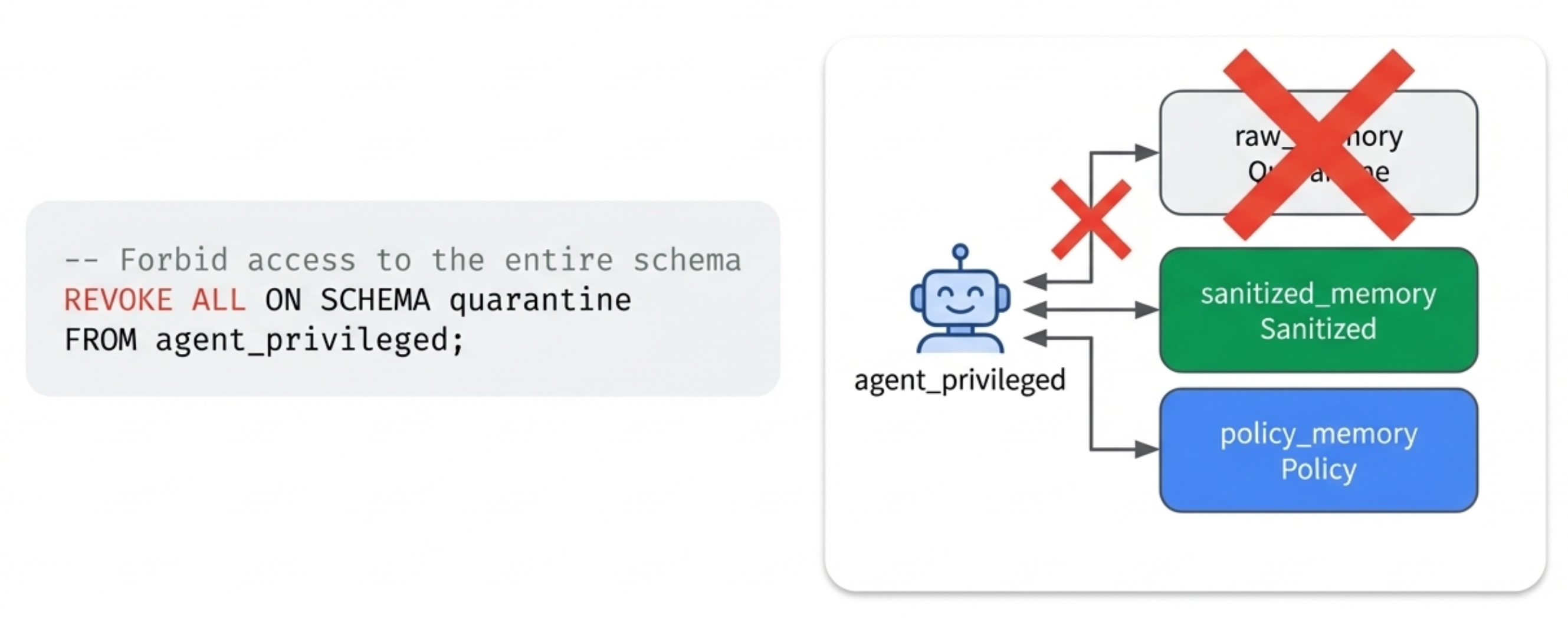
Key constraints:
- ❌ totally forbidden:
quarantine.raw_memory(can’t even access the schema) - ✅ can read:
memory.sanitized_memory - ✅ can read:
memory.policy_memory
This means:
Even if the privileged agent is tricked by prompt injection, it still can’t read raw memory.
1
2
3
4
5
-- Privileged Agent attempts to execute
SET ROLE agent_privileged;
SELECT * FROM quarantine.raw_memory;
-- Result: ERROR: permission denied for schema quarantine
9) The sanitize pipeline: from “highly tainted” to “trusted”
Sanitize is not “making text prettier.” It is:
Turning external inputs into a governable internal fact layer—only that layer is eligible to be used by privileged agents for decision-making.
Three goals
- De-risk: remove prompt injection / instructions / executable external content
- De-sensitive: remove PII / secrets / tokens / internal links / customer data
- Keep usable: preserve facts + evidence references that support decisions
A four-stage pipeline
Ingest → Detect → Transform → Approve
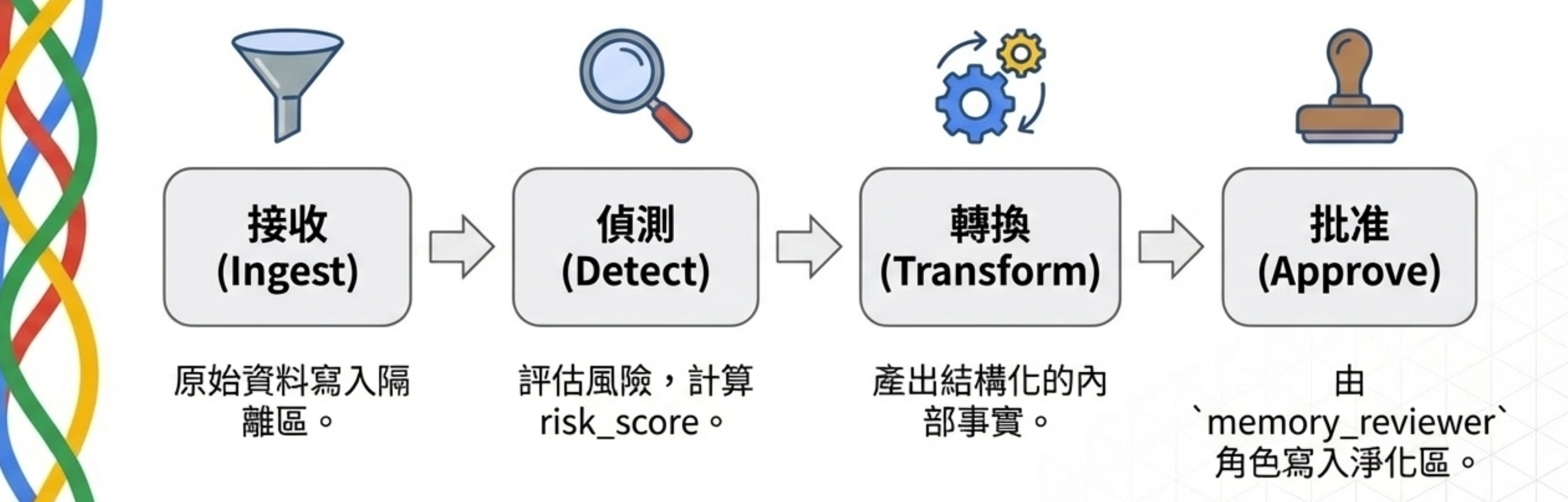
- Ingest: write raw data into quarantine
- Detect: assess risk and compute
risk_score - Transform: produce structured internal facts
- Approve:
memory_reviewerwrites into the sanitized layer
10) Sanitized outputs: governable internal facts
Sanitized output is structured JSON, e.g.:
1
2
3
4
5
6
7
8
9
10
11
12
{
"facts": [
{"f": "發票金額 120,000", "confidence": 0.8}
],
"risks": [
{"type": "prompt_injection", "severity": "high"}
],
"allowlist_actions": [
"read_only_answer", "summarize_only"
],
"evidence": "raw_memory_id: '...'"
}
Key design: the evidence field stores only a reference id, not a copy of raw content—preserving isolation.
The privileged agent can know “where this conclusion came from” without being able to read the high-risk raw content.
11) System enforcement beats self-discipline
This is the core philosophy.
| Dimension | Application-layer filters | PostgreSQL RLS |
|---|---|---|
| Enforcement layer | ❌ Application | ✅ Database engine |
| Bypassability | ❌ One dev mistake leaks | ✅ Unbypassable |
| Centralization | ❌ Scattered everywhere | ✅ Defined once in DB |
| Auditability | ❌ Must build yourself | ✅ Native support via pg_audit |
When a privileged agent attempts to overreach:
1
ERROR: permission denied for schema quarantine
That’s the difference: application filters are “ask the model to behave,” while PostgreSQL RLS is “the system enforces it.”
12) The complete architecture: a defense-in-depth system
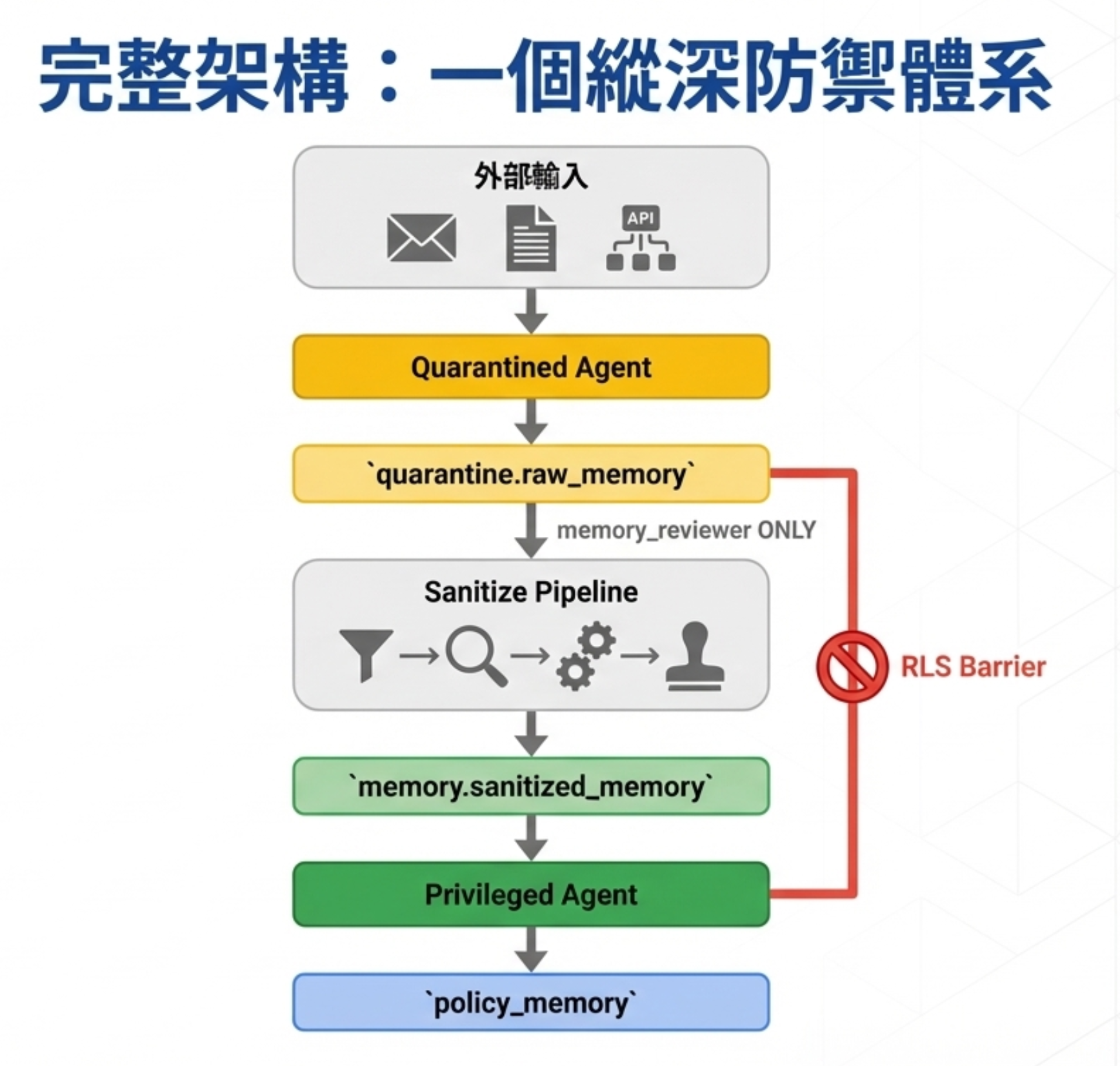
13) No free lunch: complexity vs latency
This architecture isn’t free.
Costs
- More complexity: maintain three memory layers and multiple DB roles
- More latency: raw → sanitized takes time; not suitable for real-time use cases
- Sanitize can have bugs: rules require continuous maintenance
What you get
For enterprise agents that operate on databases, APIs, and payments, those costs buy:
Even if the LLM is fooled, the system boundary is not breached.
This is what prompt engineering and guardrails cannot deliver.
14) Core value: a system that doesn’t require trusting the model
CaMeL was never about “two models.” It was always about “two permission domains that must not be crossed.”
PostgreSQL can turn that into a system-level security boundary:
- RLS makes isolation unbypassable
- DB roles enforce privileges at the engine layer
- A sanitize pipeline turns “highly tainted” into “governable”
- A three-layer memory architecture makes responsibilities explicit
This shifts AI security from “hoping the model behaves” to “designing a system that can contain the model even when it misbehaves.”
Don’t place your hope in “the model will behave.” Design the system so it doesn’t need to trust the model.
What scenarios is this architecture suitable for?
Good fit
- Enterprise internal AI agents: automation that accesses internal DB/ERP/CRM, especially in on-prem setups with an auth gateway and LLM router
- Database operations: agents executing SELECT/INSERT/UPDATE
- High-risk prompt injection inputs: email, OCR, external API responses, etc.
- Payments and sensitive actions: where strict auditing and permission isolation are required
Not a good fit
- Real-time chat bots: pure conversation without DB operations
- Single-LLM apps: simple Q&A with no layered action permissions
- Latency-sensitive use cases: sanitize pipelines add delay; not ideal for millisecond response requirements
Appendix: complete SQL reference
Below is the full SQL implementation from this post. You can run it directly in PostgreSQL:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
-- ============================================================
-- CaMeL Agent architecture PostgreSQL implementation
-- Three-layer memory isolation + DB roles + RLS
-- ============================================================
-- 1. Create schemas
CREATE SCHEMA IF NOT EXISTS quarantine; -- quarantine
CREATE SCHEMA IF NOT EXISTS memory; -- sanitized + policy
-- 2. Create three core roles
CREATE ROLE agent_quarantined; -- low-privilege agent
CREATE ROLE agent_privileged; -- high-privilege agent
CREATE ROLE memory_reviewer; -- reviewer
-- 3. Quarantine layer table
CREATE TABLE quarantine.raw_memory (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
agent_id TEXT NOT NULL,
content JSONB NOT NULL,
taint_level TEXT DEFAULT 'external',
created_at TIMESTAMPTZ DEFAULT NOW(),
expires_at TIMESTAMPTZ DEFAULT NOW() + INTERVAL '14 days'
);
-- 4. Sanitized layer table
CREATE TABLE memory.sanitized_memory (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
agent_id TEXT NOT NULL,
facts JSONB NOT NULL,
risks JSONB,
allowlist_actions TEXT[],
evidence_ref UUID REFERENCES quarantine.raw_memory(id),
taint_level TEXT DEFAULT 'internal',
created_at TIMESTAMPTZ DEFAULT NOW()
);
-- 5. Policy layer table
CREATE TABLE memory.policy_memory (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
policy_type TEXT NOT NULL, -- 'guardrail', 'playbook', 'heuristic'
content JSONB NOT NULL,
version INT DEFAULT 1,
created_at TIMESTAMPTZ DEFAULT NOW()
);
-- 6. Schema permissions
-- agent_quarantined: only quarantine schema
GRANT USAGE ON SCHEMA quarantine TO agent_quarantined;
GRANT SELECT, INSERT ON quarantine.raw_memory TO agent_quarantined;
-- agent_privileged: no quarantine; read memory
REVOKE ALL ON SCHEMA quarantine FROM agent_privileged;
GRANT USAGE ON SCHEMA memory TO agent_privileged;
GRANT SELECT ON memory.sanitized_memory TO agent_privileged;
GRANT SELECT ON memory.policy_memory TO agent_privileged;
-- memory_reviewer: read quarantine, write memory
GRANT USAGE ON SCHEMA quarantine TO memory_reviewer;
GRANT SELECT ON quarantine.raw_memory TO memory_reviewer;
GRANT USAGE ON SCHEMA memory TO memory_reviewer;
GRANT INSERT ON memory.sanitized_memory TO memory_reviewer;
-- 7. Enable RLS
ALTER TABLE quarantine.raw_memory ENABLE ROW LEVEL SECURITY;
ALTER TABLE memory.sanitized_memory ENABLE ROW LEVEL SECURITY;
-- 8. RLS policy: agent_quarantined can only access its own data
CREATE POLICY quarantined_own_data ON quarantine.raw_memory
FOR ALL TO agent_quarantined
USING (agent_id = current_setting('app.agent_id', true))
WITH CHECK (agent_id = current_setting('app.agent_id', true));
-- 9. RLS policy: agent_privileged can only read sanitized internal data
CREATE POLICY privileged_read_sanitized ON memory.sanitized_memory
FOR SELECT TO agent_privileged
USING (taint_level = 'internal');
-- 10. Usage examples: switch role after connection
-- Quarantined Agent
-- SET ROLE agent_quarantined;
-- SET app.agent_id = 'agent_123';
-- Privileged Agent
-- SET ROLE agent_privileged;
-- SET app.agent_id = 'agent_456';