OpenClaw Memory System, Fully Explained: SOUL.md, AGENTS.md, and the Painful Token Bill

Disclaimer: This post is machine-translated from the original Chinese article: https://ai-coding.wiselychen.com/openclaw-architecture-deep-dive-context-memory-token-crusher/
The original work is written in Chinese; the English version is translated by AI.
When your agent burns 5 million tokens a day, the question isn’t “Is it smart?”—it’s “Is this context construction efficient?”
Author: Wisely Chen
Date: February 2026
Series: AI Agent Architecture Notes
Keywords: OpenClaw, Context Management, Memory Architecture, Token Optimization, SOUL.md, AGENTS.md
Table of contents
- Why dissect OpenClaw’s architecture?
- File-first design: spreading the brain across the disk
- SOUL.md: saving more than pleasantries
- AGENTS.md: “do your homework” every session
- Where the token burn really comes from
- Memory flush: the cost of fighting forgetting
- Lane queues: why can’t it run in parallel?
- Security risks: the price of transparency
- Frankly
- FAQ
- Further reading
Why dissect OpenClaw’s architecture?
After I published Peter Steinberger’s Agentic Engineering philosophy, many readers asked me:
“How does OpenClaw do cross-session memory? Why not RAG?”
This question touches the soul of AI architecture.
OpenClaw doesn’t use mainstream RAG (retrieval-augmented generation). That’s not because it’s behind—it’s an intentional philosophical choice.
In short: RAG is for “looking up information,” but OpenClaw needs a “brain.”
OpenClaw is designed to be an autonomous agent, not a Q&A chatbot. That difference in requirements is why it would rather accept inefficiency than adopt classic RAG:
| Need | Chatbot + RAG | Agent + Full Context |
|---|---|---|
| What “memory” is for | Retrieve relevant info to answer a question | Continuously “know” who it is and what it’s doing |
| Context coherence | Retrieval can vary each time | Every session starts from the same cognitive baseline |
| Reasoning | Fragmented; depends on retrieved snippets | Holistic; can reason across documents |
| Persona consistency | Hard to maintain | SOUL.md ensures it’s “the same person” every time |
This is why people call OpenClaw a “token crusher.”
A user on Discord complained: running OpenClaw for a week burned $200 in Claude API fees. This isn’t rare. So this post isn’t about what OpenClaw can do (I covered that in a previous post). It’s about dissecting its context architecture—where the tokens actually go, and whether this “anti-RAG” design makes sense.
File-first design: spreading the brain across the disk
OpenClaw’s most radical design choice: store all cognitive state as plain-text Markdown files.
1
2
3
4
5
6
7
8
9
~/.openclaw/workspace/
├── SOUL.md # Persona + ethics core
├── AGENTS.md # Session logic + checklists
├── USER.md # The agent’s model of the user
├── IDENTITY.md # The agent’s self-image
├── MEMORY.md # Curated long-term memories
└── memory/
├── 2026-02-01.md # Yesterday’s short-term notes
└── 2026-02-02.md # Today’s short-term notes
How is this different from Claude Code’s CLAUDE.md?
Claude Code’s CLAUDE.md is an instruction set—telling the agent what to do.
OpenClaw’s full set is a cognitive system—letting the agent know who it is, what it remembers, and what it must read.
The upside is transparency: you can edit these files directly and immediately change the agent’s behavior.
The downside? Every new session has to reread the whole stack.

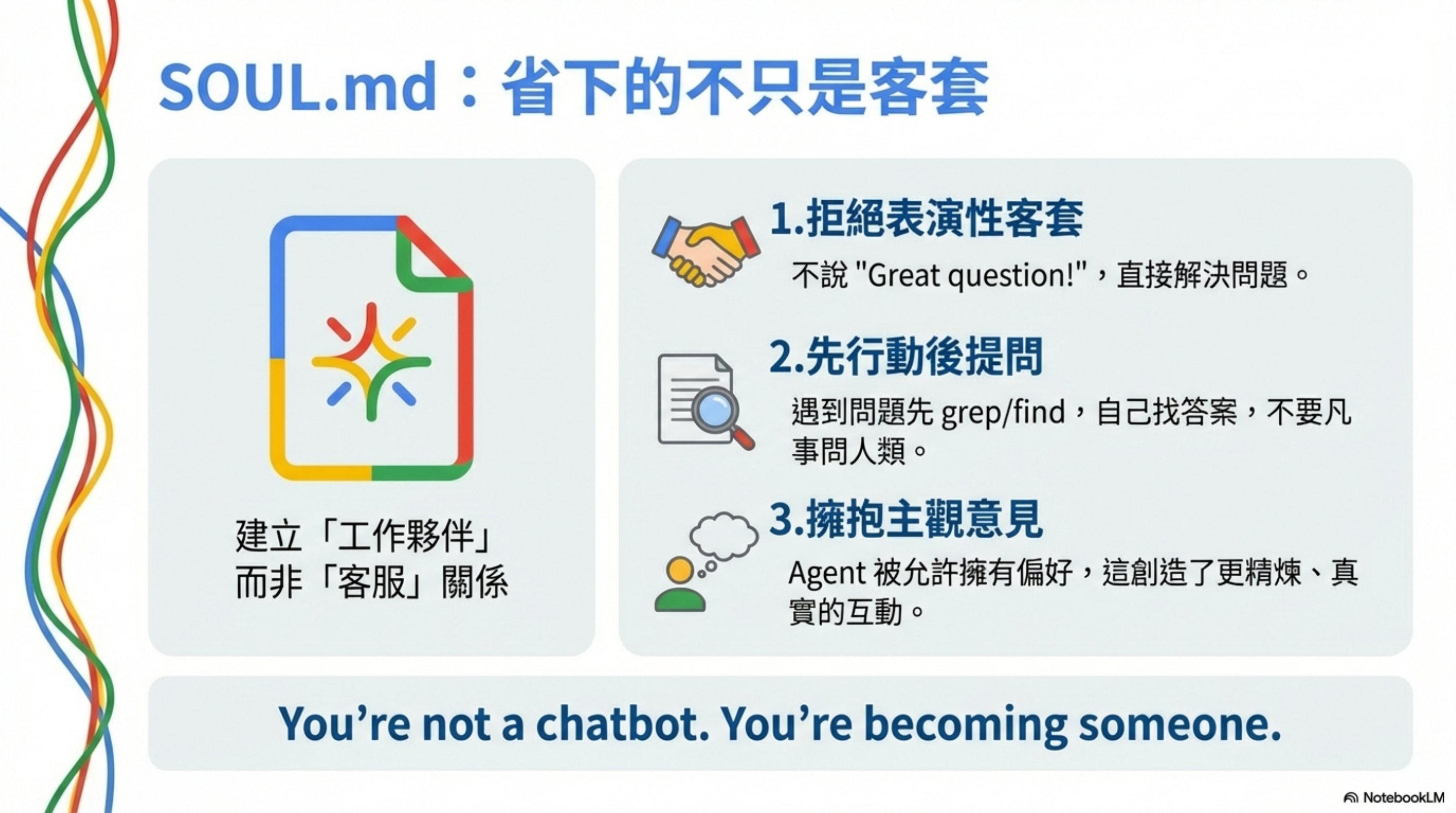
SOUL.md: saving more than pleasantries
SOUL.md is OpenClaw’s “soul” document. The first line sets the tone:
You’re not a chatbot. You’re becoming someone.
It defines several key principles.
1. No performative politeness
1
2
3
Be genuinely helpful, not performatively helpful.
Skip the "Great question!" and "I'd be happy to help!" — just help.
Actions speak louder than filler words.
This isn’t about saving tokens. Saving a few hundred tokens a day is irrelevant compared to total usage (130k+).
The real goal is to establish a “work partner” interaction model—not a customer-service bot.
When your agent stops opening with canned pleasantries, it answers more directly, more like a colleague who knows you. That’s persona design, not cost optimization.
2. Act before asking
1
2
3
4
Be resourceful before asking.
Try to figure it out. Read the file. Check the context. Search for it.
Then ask if you're stuck.
The goal is to come back with answers, not questions.
Operationally, this rule pushes the agent to call tools proactively.
Instead of “Which file should I read?”, it will grep, find, cat its way to an answer.
That reduces back-and-forth confirmation rounds—but increases tool-call output and token usage.
3. Embrace opinions
1
2
3
Have opinions.
You're allowed to disagree, prefer things, find stuff amusing or boring.
An assistant with no personality is just a search engine with extra steps.
This looks unrelated to tokens, but it shapes response behavior: the agent tends to give shorter, more decisive answers instead of long “both sides” responses.
4. Memory is existence
The final section states OpenClaw’s memory philosophy:
1
2
Each session, you wake up fresh. These files *are* your memory.
Read them. Update them. They're how you persist.
This line directly explains why OpenClaw has to “do its homework” every session—because those Markdown files are its memory substrate.
SOUL.md’s design says: accept some startup reading cost to get tighter conversations, plus cross-session memory continuity.
AGENTS.md: “do your homework” every session
This is the first big chunk of token burn.
AGENTS.md starts with: “This folder is home. Treat it that way.” Then it defines a mandatory boot sequence:
1
2
3
4
5
6
7
8
9
## Every Session
Before doing anything else:
1. Read `SOUL.md` — this is who you are
2. Read `USER.md` — this is who you're helping
3. Read `memory/YYYY-MM-DD.md` (today + yesterday) for recent context
4. **If in MAIN SESSION** (direct chat with your human): Also read `MEMORY.md`
Don't ask permission. Just do it.
Note the last line: Don’t ask permission. Just do it.
That’s why OpenClaw proactively reads these files on every startup: it’s designed to “do, not ask.”
| Startup step | Action | Token cost |
|---|---|---|
| 1 | Read SOUL.md | ~800 tokens |
| 2 | Read USER.md | ~500 tokens |
| 3 | Read today’s memory | ~1,000–3,000 tokens |
| 4 | Read yesterday’s memory | ~1,000–3,000 tokens |
| 5 | Read MEMORY.md (main session only) | ~1,000–2,000 tokens |
Per new session, just “reading homework” costs 4,000–10,000 tokens.
And that cost repeats for every fresh conversation.
The two-layer memory design
AGENTS.md also defines two memory layers:
1
2
- **Daily notes:** `memory/YYYY-MM-DD.md` — raw logs of what happened
- **Long-term:** `MEMORY.md` — your curated memories, like a human's long-term memory
Daily logs are raw; MEMORY.md is curated long-term memory—similar to human working memory vs long-term memory.
A key security choice: MEMORY.md is only loaded in the main session, not in group chats (Discord/WhatsApp), because:
1
This is for **security** — contains personal context that shouldn't leak to strangers
That’s a deliberate trade-off: sacrifice some memory continuity in groups to protect privacy.
How this differs from Claude Code
Claude Code’s CLAUDE.md is injected once into the system prompt; it isn’t reread repeatedly.
OpenClaw “re-learns itself” every session—and does so by actively calling tools, not via passive injection.
That’s the mechanism enabling cross-session memory—and the first source of its token-crushing cost structure.

Where the token burn really comes from
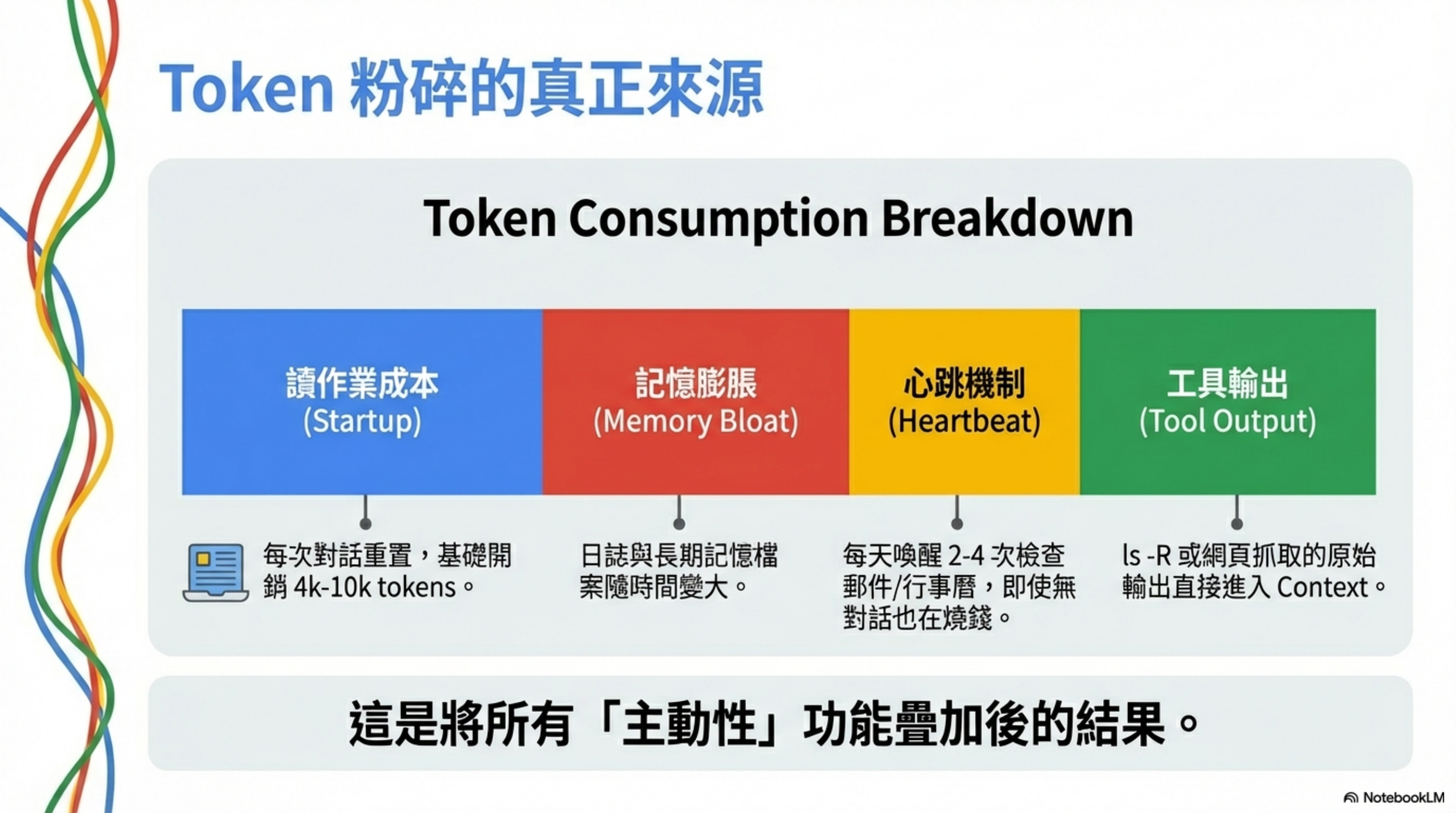
Why do so many people complain OpenClaw is expensive? Architecturally, the major cost centers are:
1. “Homework” on every new session
As explained above: every new session reads SOUL.md, USER.md, memory files.
This isn’t a one-time setup cost—it repeats every new conversation.
2. Memory files keep growing
memory/YYYY-MM-DD.md grows daily; MEMORY.md grows over time. As usage accumulates, these files get bigger.
AGENTS.md suggests periodic maintenance, but few people actually curate them. Result: memory files bloat, and read cost increases.
3. The hidden cost of heartbeats
AGENTS.md defines a heartbeat mechanism—the agent wakes periodically to check email, calendars, social notifications, etc.
1
2
3
4
5
**Things to check (rotate through these, 2-4 times per day):**
- **Emails** - Any urgent unread messages?
- **Calendar** - Upcoming events in next 24-48h?
- **Mentions** - Twitter/social notifications?
- **Weather** - Relevant if your human might go out?
Each wake-up reloads context and calls tools. It’s background burn: you’re not chatting, but tokens are still being consumed.
4. Tool outputs aren’t capped
When the agent runs ls -R or fetches a web page, raw output can be injected into context. If that output is long, token usage spikes.
This isn’t unique to OpenClaw, but its “do first, ask later” design amplifies the effect: it calls tools more aggressively, so you see more tool output.
Why “token crusher”?
Not because any single feature is uniquely expensive, but because all of these costs stack:
- Homework on every new session
- Memory bloat
- Background heartbeats
- Unbounded tool output
And OpenClaw encourages proactivity—proactive action, memory, and checks—all of which cost tokens.
This is a capability-vs-cost trade-off, not a design mistake.
Memory flush: the cost of fighting forgetting
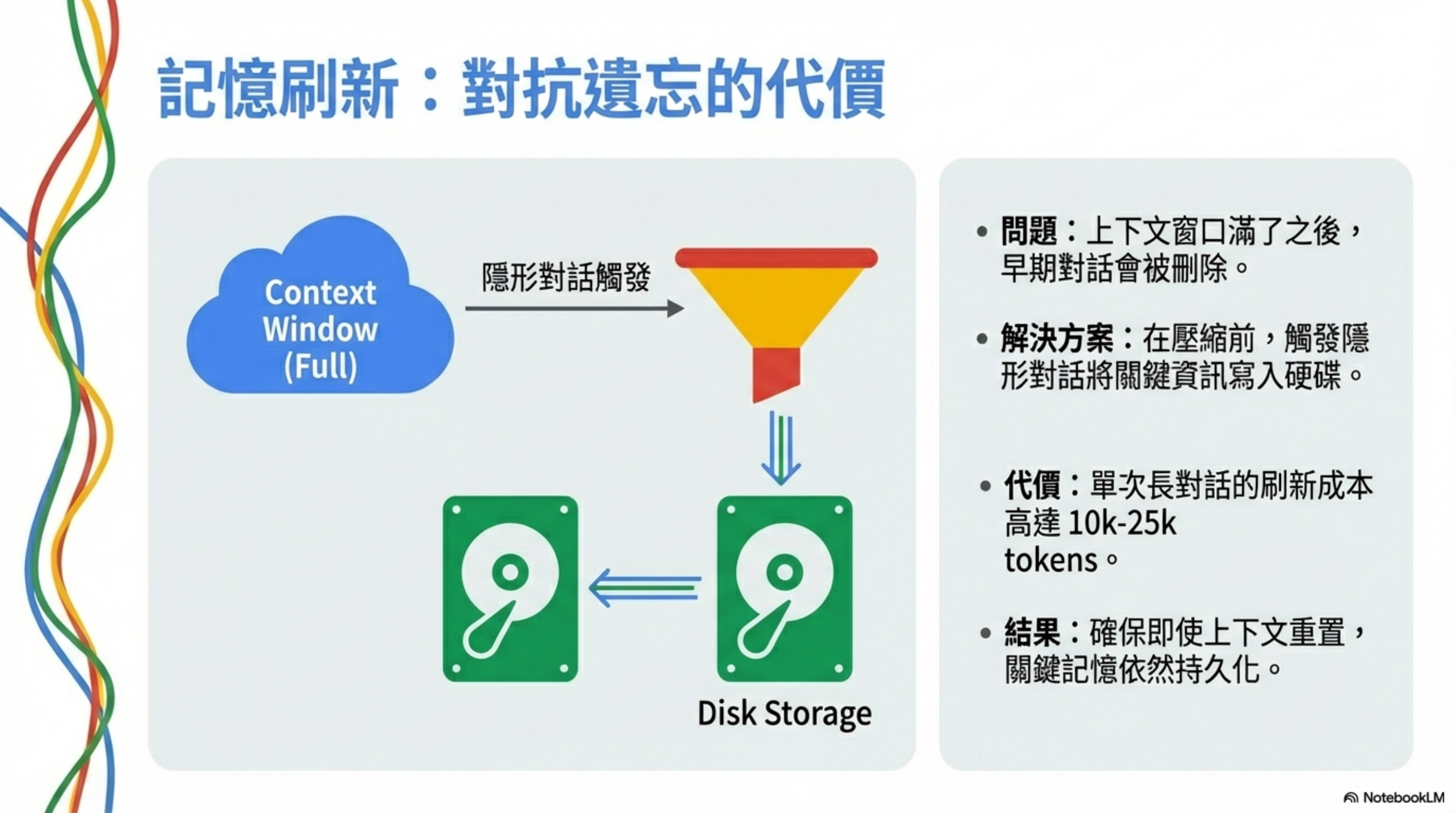
One of OpenClaw’s most innovative ideas is “pre-compression memory flush.”
The problem: context windows are finite
When an agent approaches the context limit, systems “compress”—often by dropping early conversation history.
That makes the agent forget what you asked 10 minutes ago.
The solution: persist before compressing
OpenClaw’s approach:
- Continuously monitor token usage
- When nearing a threshold (default ~4,000-token buffer), trigger an invisible system turn
- System prompt: “Session nearing compaction. Store durable memories now.”
- Agent writes key info into
memory/YYYY-MM-DD.md - Only then perform compression
So even if raw chat history is removed, key information is already persisted to disk.
The cost
Each flush:
- System prompt: ~500 tokens
- Agent thinking + writing: ~2,000–5,000 tokens
- Long conversations may trigger 3–5 times
Memory-flush cost per long conversation: 10,000–25,000 tokens
Claude Code doesn’t pay this cost: it doesn’t do cross-session memory, so it doesn’t need this mechanism.
Lane queues: why can’t it run in parallel?
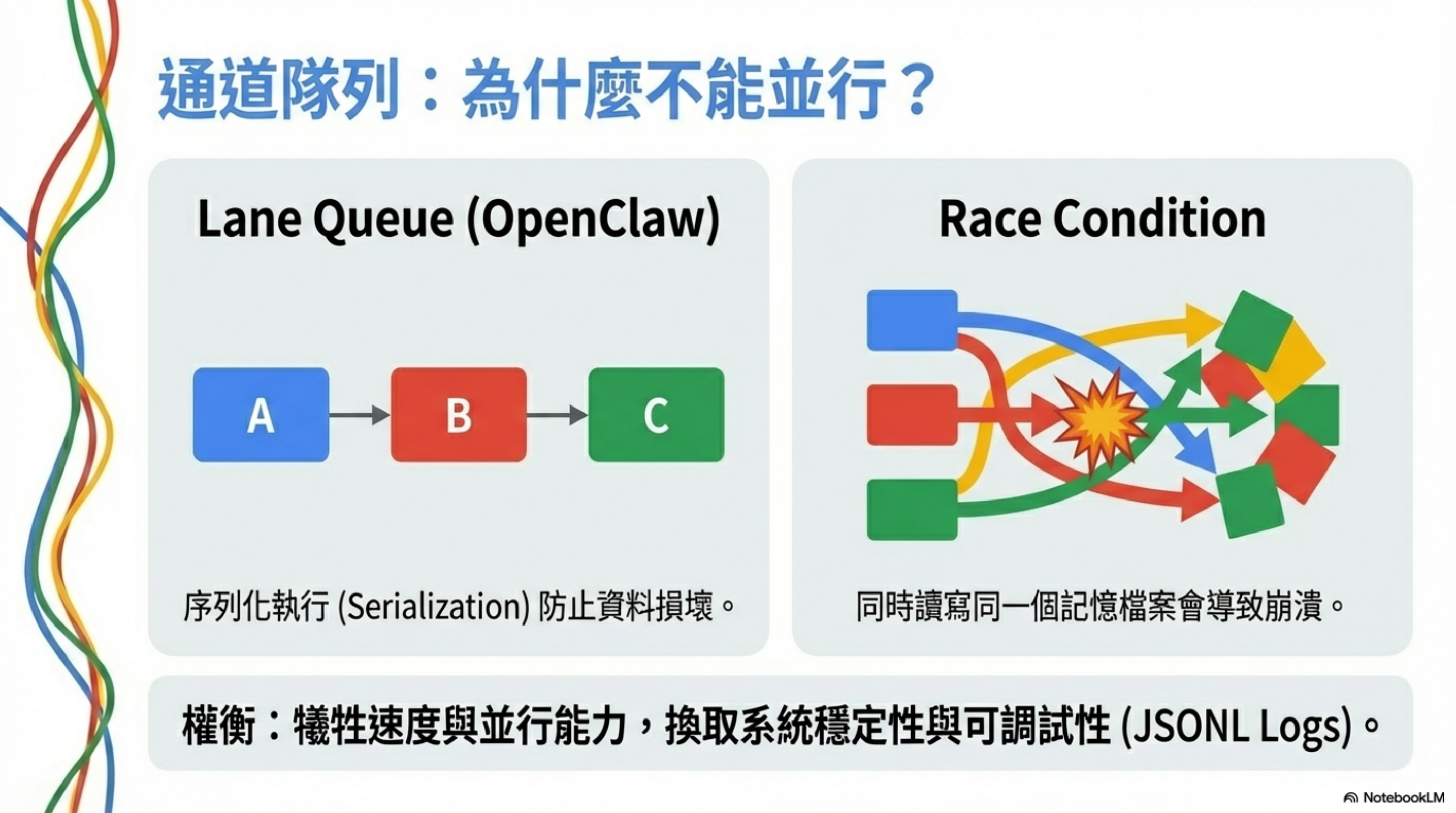
OpenClaw uses a “lane queue” architecture—tasks within the same lane must execute strictly sequentially.
That sounds slow, but it’s justified.
The problem: race conditions
If the agent tries to:
- read
memory/2026-02-02.md - write
memory/2026-02-02.md
at the same time, you risk corruption.
The solution: serialization
Each task waits for the previous task to fully complete:
1
Task 1 (read) → done → write log → Task 2 (write) → done → write log → ...
The trade-off
- Can’t fully exploit parallelism
- Long tasks block subsequent tasks
- Overall throughput is slower
In exchange you get stability and debuggability.
Every operation is recorded in JSONL; you can reconstruct the exact ordering of events.
Security risks: the price of transparency
Storing memory as plain Markdown introduces two primary risks:
1. No encryption — personal preferences, projects, and habits in USER.md become fully exposed if the host is compromised.
2. Prompt injection — if the agent auto-reads WhatsApp/Discord messages, malicious instructions can be embedded in normal messages and trick the agent into dangerous actions.
OpenClaw has partial defenses (allowlists, main-session isolation), but not enough against professional attackers. That’s why my hardening guide emphasizes: assume it will be breached.
Frankly
Back to the opening question: why doesn’t OpenClaw use RAG?
Because RAG is for “looking up information,” but OpenClaw needs a “brain.”
That architectural choice determines everything:
- File-first design gives the agent a durable cognitive system
- “Homework” at startup ensures it remembers who it is
- Two-layer memory (daily notes + MEMORY.md) mirrors human working vs long-term memory
- Heartbeats let it proactively check in on your life
The price is token usage. But it’s not a bug—it’s the cost structure you accept if you want an agent that “remembers you” like an employee.
So it’s not just a token crusher. It’s a digital brain with memory, persona, and proactive behavior. You’re not paying for tokens—you’re paying for persistence.
FAQ
Q: What’s the fundamental difference between OpenClaw and Claude Code’s CLAUDE.md?
CLAUDE.md is an instruction set injected once into the system prompt and not reread. OpenClaw’s SOUL.md + AGENTS.md + memory/*.md is a cognitive system: every startup the agent proactively calls tools to reread them—effectively “relearning itself.” That’s the key to cross-session memory, and also the primary source of token cost.
Q: Why not use RAG to reduce costs?
RAG is great for “lookup” in Q&A. OpenClaw’s goal is autonomous agency: continuously knowing who it is and what it’s doing. Fragmented retrieval can’t provide a stable persona and coherent baseline context, so OpenClaw chooses full context despite inefficiency. It’s philosophy, not technical inferiority.
Q: Is $200/week in API costs normal?
Depends on intensity. If heartbeats are enabled (2–4/day), you chat frequently, and memory files aren’t curated, it’s plausible. Main costs are: homework at session start (4k–10k tokens), memory flushes (10k–25k tokens per long conversation), and heartbeat wake-ups (each reloads context). To reduce cost, disable heartbeats, curate memory/*.md, and avoid very long sessions.
Q: What should you do about memory bloat?
AGENTS.md suggests maintenance, but most people don’t do it. My recommendation: check memory/*.md size weekly; if a daily file exceeds ~5KB, consider summarizing; move key info into MEMORY.md (curated); keep daily logs for only the last 7 days. This can keep per-startup reads under ~5,000 tokens.
Q: How do you mitigate security risks?
Two big risks: plaintext memory (a compromised host exposes everything) and prompt injection (malicious content in group messages). Mitigations: don’t write sensitive info into USER.md; restrict WhatsApp/Discord allowlists; run OpenClaw on an isolated VM; periodically audit memory/*.md for anomalies. See my hardening guide for details.
Q: Is this architecture suitable for enterprise use?
Frankly, not yet. Reasons: unpredictable costs (token burn depends heavily on usage), high security risk (plaintext memory + prompt injection), and limited enterprise-grade auditing (JSONL logs exist, but it’s not enterprise governance). If an enterprise needs similar capabilities, consider Claude Code plus a custom memory layer, or wait for an enterprise-ready OpenClaw (if it ever appears).
Further reading
- From $116M retirement to Agentic Engineering: Peter Steinberger and the legendary development philosophy behind OpenClaw — the person and philosophy behind OpenClaw
- From “wrapper 1.0” to “wrapper 2.0”: why Anthropic should be the one sweating — the full analysis of the wrapper-2.0 ecosystem
- OpenClaw four-layer defense-in-depth hardening guide — must-read if you want to run OpenClaw
- OneFlow: rethinking Single Agent vs Multi-Agent — why context management matters more than stacking agents
- Personal AI Assistant Showdown Week: Claude Code vs OpenClaw — different paths, same destination — comparing the two routes
About the author:
Wisely Chen, Head of R&D at NeuroBrain Dynamics Inc., with 20+ years in IT. Former Google Cloud consultant, VP of Data & AI at Yunglien Logistics, and Chief Data Officer at iCharging. Focused on practical enterprise AI transformation and real-world agent adoption.
Links:
- Blog: https://ai-coding.wiselychen.com
- LinkedIn: https://www.linkedin.com/in/wisely-chen-38033a5b/